
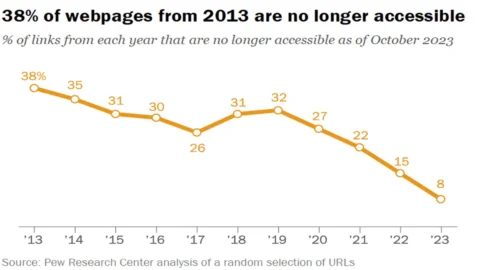
Il 38% delle pagine web esistenti nel 2013 non è più accessibile a dieci anni di distanza dalla creazione. Lo dice uno studio del centro di ricerca statunitense “Pew”, che fornisce informazioni su problemi sociali, opinione pubblica e andamenti demografici. Per capire bene il significato dell’esito di questa analisi occorre, prima di tutto, stabilire cosa s’intende per “pagine non più accessibili” e definire il criterio di estrazione dei dati.
Il punto di partenza è il campione utilizzato. Si tratta delle pagine prelevate dal repository web di Common Crawl, un’organizzazione no-profit che esegue la scansione di tutto il web e fornisce gratuitamente al pubblico i propri archivi e set di dati. L’archivio è costituito da petabyte di dati raccolti a partire dal 2008. In genere, le scansioni vengono completate ogni mese, quindi, i ricercatori di Pew hanno dovuto prelevare e analizzare ben 120 pacchetti, ciascuno corrispondente ad un mese di un determinato anno a partire dal 2013 e fino al 2023. L’analisi prevede quindi un riscontro, eseguito non certo da una persona, quanto piuttosto da una routine software (realizzata tramite il linguaggio di programmazione Python), tra il contenuto presente ad un certo indirizzo e corrispondente ad una particolare data e il contenuto presente oggi allo stesso indirizzo. L’esito di questo test non può dare risultati diversi da:
- errore 204 (nessun contenuto)
- errore 400 (richiesta errata)
- errore 404 (pagina non trovata)
- errore 410 (pagina rimossa)
- errore 500 (errore interno del server)
- errore 501 (errore nel metodo della richiesta)
- errore 502 (errore di connessione)
- errore 503 (servizio non disponibile)
- errore 523 (origine del contenuto irraggiungibile)
oppure da:
- pagina modificata in maniera lieve
- pagina modificata in maniera radicale
- indirizzo che rimanda ad un altro contenuto (pagina spostata) che può rientrare nei 2 casi precedenti.
Nel campione sono presenti solo:
- pagine da siti web governativi (identificati tramite i dati del provider dei domini .gov)
- siti di notizie (identificati utilizzando i dati della società di metrica dell’audience “comScore”)
- pagine dell’enciclopedia online Wikipedia
- pagine dei singoli post pubblici del social media X/Twitter
Per stilare il rapporto, i ricercatori si sono concentrati solo sugli errori codificati (dall’errore 204 all’errore 523), cioè su pagine che davvero non sono più reperibili in alcun modo, per diversi motivi. Le altre definizioni di accessibilità esulano dallo scopo della ricerca. Le pagine sono state quindi considerate accessibili in tutti gli altri casi, comprese situazioni ambigue in cui non si poteva garantire l’esistenza del contenuto, come pagine “soft 404” o timeout non causati dal DNS (cioè tempi di attesa troppo lunghi per recuperare le pagine originali).
Le conclusioni oggettive dello studio sono che circa un quarto di tutte le pagine web esistenti tra il 2013 e il 2023 non sono più accessibili (nell’accezione poco sopra indicata) a partire da ottobre 2023. Nella maggior parte dei casi, ciò è dovuto al fatto che una singola pagina è stata cancellata o rimossa su un sito web altrimenti funzionante. Ovvero, è il singolo contenuto che è stato cancellato, non tutto il sito.
Ad esempio, il 23% delle pagine web di notizie contiene almeno un collegamento non funzionante, così come il 21% delle pagine web dei siti governativi. I siti di notizie con un livello elevato di traffico e quelli con un livello inferiore hanno la stessa probabilità di contenere collegamenti interrotti. È particolarmente probabile che le pagine web del governo a livello locale (quelle appartenenti alle amministrazioni cittadine) contengano collegamenti interrotti. Il 54% delle pagine di Wikipedia contiene almeno un collegamento nella sezione “riferimenti” che punta a una pagina che non esiste più. Su X/Twitter, quasi un un tweet su cinque non è più pubblicamente visibile, anche solo pochi mesi dopo essere stato pubblicato. Nel 60% di questi casi, l’account che originariamente aveva pubblicato il tweet è stato reso privato, sospeso o cancellato del tutto. Nel restante 40% il titolare dell’account ha cancellato il singolo tweet, ma l’account esiste ancora. Alcuni tipi di tweet tendono a scomparire più spesso di altri. Oltre il 40% dei tweet scritti in turco o arabo non sono più visibili sul sito entro tre mesi dalla pubblicazione. E i tweet provenienti da account con le impostazioni predefinite del profilo hanno maggiori probabilità di scomparire dalla vista del pubblico.
Cosa significano questi dati?
Ancora una volta occorre una premessa: non possiamo escludere che potrebbero esserci stati alcuni vizi di classificazione dei dati etichettati come “non disponibili”. Questo perché, per motivi di sicurezza, taluni siti cercano attivamente di impedire il tipo di raccolta automatizzata dei dati che è stata realizzata attraverso questa indagine. Detto questo, i motivi, più che legittimi e che non devono destare alcuna preoccupazione o rammarico, per cui una pagina scompare da Internet nell’arco di 10 anni, possono essere:
- rimozione nell’ambito della normativa europea sulla protezione dei dati (GDPR)
- rimozione ai sensi e per gli effetti della decisione della Corte di giustizia dell’Unione europea (CGUE) relativa al diritto all’oblio
- rimozione imposta dalla legge in generale (diffamazione, procurato allarme, stampa clandestina, esercizio abusivo di varie professioni, etc…)
- rimozione per contenuti non più validi e assenza di aggiornamenti in merito
- scadenza delle informazioni contenute all’interno delle pagine
- landing page a pagamento, non più utilizzate
- mancato pagamento per il mantenimento del dominio
- violazione dei diritti d’autore
- mancanza di fondi per il sostegno di un progetto editoriale
- auto-emendamento (X/Twitter)
- occultamento volontario di prove
- cattiva gestione della migrazione di un sito web
- cancellazione involontaria
- disattivazione sistemi di traduzione automatica
- disattivazione sistemi di generazione automatica di contenuti
- disattivazione sistemi di aggregazione di contenuti
- variazione della URL della pagina senza opportuno reindirizzamento
In sostanza non c’è alcun margine per poter utilizzare questi dati come indicazione sui comportamenti di chi genera contenuti sul web. Non è altresì possibile stabilire se la scomparsa delle pagine di Internet, a distanza di anni, sia un bene o sia un male. A volte, si tratta solo del rispetto delle leggi, di decisioni politiche o personali, di correzioni o di aggiornamenti. Forse, l’unica riflessione valida da fare è quella che ruota intorno alla responsabilizzazione dei cosiddetti “utenti attivi” di Internet, cioè di tutti quelli che, in un modo o nell’altro, generano alcuni dei contenuti del web: siano essi dei semplici contributori dell’enciclopedia online “Wikipedia” o del social network X/Twitter, siano essi degli editori digitali o dei responsabili di questo o quel sito governativo. Troppo spesso, questi soggetti, si lamentano della difficoltà nel reperire informazioni su Internet, dell’incongruenza dei risultati o peggio, dell’insoddisfacente posizionamento delle loro fonti preferite, dimenticando di essere loro stessi parte del problema. Valga per tutti l’esempio di chi, variando la URL di una pagina senza fare l’opportuno reindirizzamento, non fa che rendere Internet un posto peggiore: un mondo virtuale pieno di spazzatura digitale, formata da tante richieste che cadono nel vuoto e, al tempo stesso, di contenuti che non saranno più reperibili. Internet, da quando si è consolidata, ha una sua netiquette (buone regole di comportamento per gli utenti) che andrebbe letta e rispettata da tutti*.
Se, in ultima analisi, ci fosse qualcuno che ritenesse la scomparsa delle pagine Internet, laddove venisse imposta, sempre un male, questi non dovrebbe far altro che adoperarsi per far cambiare le specifiche leggi, causa della cancellazione.
*cfr. request for comments: 1855 (netiquette guidelines): “remember that setting up an information service is more than just design and implementation. It’s also maintenance”.



