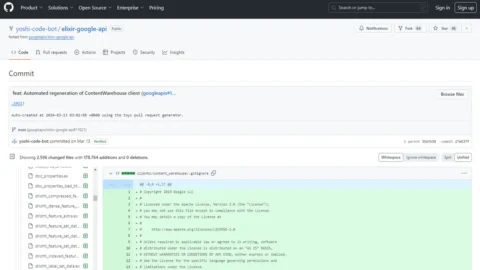
Il 13 marzo 2024, migliaia di documenti (2.596), che sembrano provenire dal “Content API Warehouse” interno di Google, sono stati rilasciati su GitHub da un bot automatizzato chiamato yoshi-code-bot. Si tratta di documentazione in merito al funzionamento di determinati parametri utilizzati dall’algoritmo di posizionamento di Google. Ad accorgersi di questa pubblicazione è un ingegnere iraniano, Erfan Azimi, esperto di SEO, che – a fine maggio – notifica la presenza dei file a Rand Fishkin, uno dei fondatori di Moz, sito che rappresenta il punto di riferimento internazionale per il SEO e che tiene traccia, dal lontano 2000, di tutti i cambiamenti dell’algoritmo di Google, ufficiali e non. Fishkin chiede aiuto a Michael King, altro esperto SEO, che è in possesso di ulteriori informazioni che possono essere incrociate con i dati trapelati.
I due pubblicano la loro analisi comparativa. Nel senso che mettono a confronto quanto si evince dai documenti con quanto di ufficiale Google ha sempre diffuso in merito al proprio algoritmo. Big G si trova costretta a commentare l’accaduto, ma lo fa in maniera del tutto scontata: dice – in sostanza – che le ipotesi sul funzionamento del proprio algoritmo sono formulate sulla base di informazioni incomplete, datate e decontestualizzate, quindi prive di fondamento. Di fatto, però, conferma la paternità dei documenti. Si tratta di una “fuga di dati“. Ed è forse la più grande fuga di notizie che l’azienda si trova ad affrontare negli ultimi tempi.
Ma perché Google non approfitta per commentare, uno per uno, ogni elemento specifico, confermandone o smentendone la validità? Sarebbe la migliore occasione per fugare ogni dubbio sulla propria trasparenza e quella del suo algoritmo. Chiaramente, chi si fa una domanda del genere pecca in ingenuità, perché Google – finora – tutto ha fatto tranne che essere chiara sulle dinamiche che regolano il posizionamento dei risultati delle sue ricerche. La giustificazione per tale comportamento non è altro che il filo del rasoio su cui abilmente cammina chiunque parli a nome del colosso di Seattle: se Google rilasciasse una guida passo-passo, gli spammer e/o i malintenzionati potrebbero utilizzarla per manipolare le classifiche. In sostanza, per Google, il segreto aziendale tutela tanto l’azienda, quanto l’utente finale.
A questo punto, l’articolo potrebbe concludersi senza ulteriori riflessioni, perché le giustificazioni di Google sono tanto ragionevoli quanto maliziose. I lettori potrebbero distribuirsi equamente tra chi parteggia comunque per la totale trasparenza e chi invece ritiene più giusto tutelare l’ingegno di chi ha creato l’algoritmo. Eppure, c’è una considerazione molto più importante da fare, a fronte di una domanda: Google, finora, ci ha mentito? Leggendo tutta la documentazione (14.014 attributi/istruzioni), aiutati da alcuni strumenti online e anche dall’IA, ci s’imbatte in alcuni dettagli chiari sui parametri di ranking (signals) che Google storicamente ha detto di non utilizzare, che invece sembrano avere un ruolo importante nell’algoritmo. Non avendo intenzione di entrare nei dettagli, per le ragioni già esplicitate, a Google basta dire che ciò che è contenuto nel documento potrebbe non essere mai stato utilizzato, essere stato testato per un periodo di tempo, essere cambiato nel corso degli anni o sì, essere utilizzato. Insomma: tutto e il contrario di tutto. Però, non possiamo saperlo.
L’unica certezza è che però quei file corrispondono perfettamente alla documentazione con la quale ha a che fare qualunque team di Google che si occupi dell’algoritmo. Lo confermano gli ex dipendenti di Google, ma anche il buonsenso, considerando che, altri leaks che sono stati pubblicati nei repository GitHub pubblici utilizzano lo stesso stile di notazione, formattazione e persino nomi e riferimenti a processi/moduli/funzionalità. La stessa identica struttura si ritrova poi anche nella documentazione dell’API Cloud di Google. Tutto assomiglia, in sostanza, ad una spiegazione dei vari attributi e moduli API per aiutare a familiarizzare coloro che lavorano al progetto, con questi elementi. Facendo un’analogia con una biblioteca, il documento trapelato è al pari di un inventario dei libri, una sorta di catalogo a schede, che informa i dipendenti cosa è disponibile, come possono ottenerlo e cosa contiene.
Ma torniamo al dettaglio delle presunte bugie. Quali sono le principali affermazioni fatte pubblicamente da Google in contrasto con quanto trovato nei documenti trapelati?
1 – Non abbiamo parametri che fanno riferimento all’autorità del dominio/sito.
–>Nei documenti trapelati, esiste un parametro che si chiama “siteAuthority”.
2 – Non utilizziamo il monitoraggio dei click sui risultati delle ricerche per aggiornare i ranking.
–>Nei documenti trapelati, esistono dei parametri che chiamano in causa proprio i click del mouse (numero, durata della lettura post click, provenienza, etc…).
3 – Non trattiamo diversamente un sito appena nato rispetto ad uno registrato da molto più tempo.
–>Nei documenti trapelati esiste il parametro “hostAge” per determinare da quanto tempo esiste il sito.
4 – Non utilizziamo alcun tipo di dato proveniente dal browser per il ranking.
–>In altri documenti trapelati esiste una pagina di una presentazione che menziona i dati prelevati da Chrome (il browser di Google) come sorgente per i feedback sulle visite di una particolare pagina. Questo potrebbe spiegare il parametro “chromeInTotal”, presente nei documenti trapelati e di fatto conferma che il prelievo dei dati può avvenire anche dal browser.
N.B.: qui si potrebbe configurare anche un grosso problema per quanto riguarda la privacy degli utenti
5 – Google ha sempre parlato di “un algoritmo” che ha lasciato a noi immaginare come una gigantesca espressione matematica con una serie di fattori di ranking ponderati.
–>In base ai diversi sistemi a cui si fa riferimento nella documentazione potrebbero esserci più di cento diversi sistemi di classificazione. Ciascuno dei sistemi separati rappresenta quello che Google chiama “signals”, cioè “segnale di posizionamento”. Insomma, nessun algoritmo vero e proprio, ma un processo molto complesso che elabora i diversi input e non è mai sempre lo stesso.
Ovviamente, insieme a tanti parametri in contrasto con quanto riferito pubblicamente da Google, ci sono anche delle conferme. Ovvero tanti “signals” che costituiscono l’ABC per chiunque si occupi di SEO. Si va dall’importanza dei link in entrata provenienti da fonti autorevoli, all’importanza della data (contenuti più recenti vengono premiati) o dell’autore (contenuti senza autore vengono penalizzati). Nei documenti trapelati si può leggere anche di esplicite penalizzazioni verso quelle pagine che utilizzano anchor text per i link in uscita che non corrispondono all’argomento della pagina di destinazione. Dal funzionamento di determinati parametri si capisce anche che Google predilige le fonti locali per le informazioni locali. Si sapeva, ma ne abbiamo ora la conferma, che Google scansiona le pagine badando anche ai formati, oltre che strutturali, anche grafici e stilistici: si parla cioè di attenzione alla lunghezza del contenuto, all’utilizzo di titoli con caratteri più grandi, insomma alle buone norme generali della produzione per il web.